
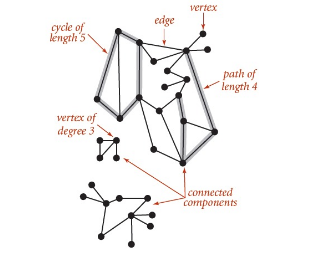
无向图
图的定义:A graph is a set of vertices and a collections of edges that each connect a pair of vertices.
graph = edge + vertex
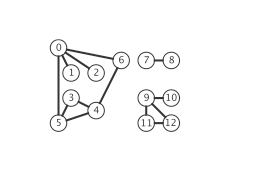
图的表示
邻接矩阵
假设图有V个顶点,使用一个V*V的布尔矩阵a来表示图,顶点v和顶点w相连那么a[v,w]和a[w,v]都设置为true,相连设置为false。
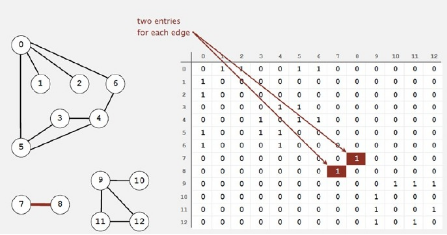
邻接矩阵在存储一个较大的图时是不可行的,所需要的巨大的空间无法满足。
邻接表
邻接表是一个一顶点vertex为索引的列表数组,每一个索引代表一个顶点,数组在该索引处的元素是和该顶点相连接的顶点列表。
使用邻接表实现的图有如下特点:
- 创建图使用的空间和V+E成正比
- 添加一条边时间为常数
- 遍历顶点v相邻的顶点所需时间和v的度数成正比
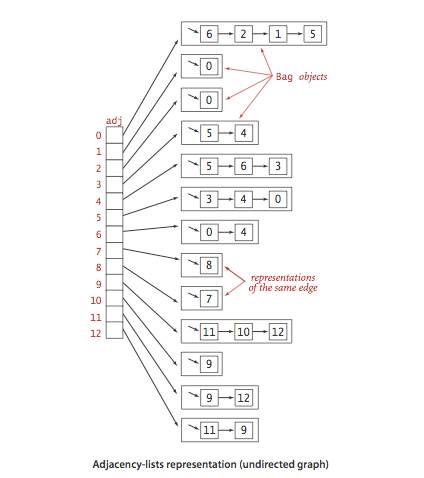
用邻接表创建的Graph数据结构:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43public class Graph {
private int V; //顶点数目
private int E; //边的条数
private Bag<Integer>[] adj; //邻接表
public Graph(){}
//初始化顶点为V的邻接表
public Graph(int V){
this.V=V;
this.E=0;
adj=(Bag<Integer>[]) new Bag[V];
for(int i=0;i<V;i++){
adj[i]=new Bag<Integer>();
}
}
public int V(){
return V;
}
public int E(){
return E;
}
public void addEdg(int v,int w){
adj[v].add(w);
adj[w].add(v);
E++;
}
public Iterable<Integer> adj(int v){
return adj[v];
}
public int degree(int v){
return adj[v].size();
}
public String toString(){
String s=V+" vertices"+E+" edges\n";
for(int i=0;i<V;i++){
s+=i+":";
for(int j:this.adj[i]){
s+=j+" ";
}
s+="\n";
}
return s;
}
}
深度优先搜索
深度优先搜索类似于走迷宫的Tremaux搜索。
从一个没有走过的路口开始,走过的路铺一条绳子;
标记走过的路口;
当来到标记的路口,一直回退到有没被标记的路口继续走,如果回退时一直无路可走就一直回退到起点。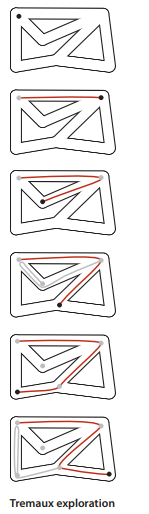
深度优先搜索类似于走迷宫,一直寻找没有被访问的节点
深度优先搜索需要用递归的方法遍历图中所有的顶点
- 将访问的节点标记
- 递归的访问它的所有没有被标记的邻居节点
深度优先代码如下:
1 | public class DFS{ |
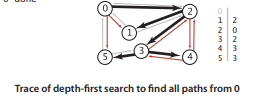
下面是DFS的搜索轨迹图:
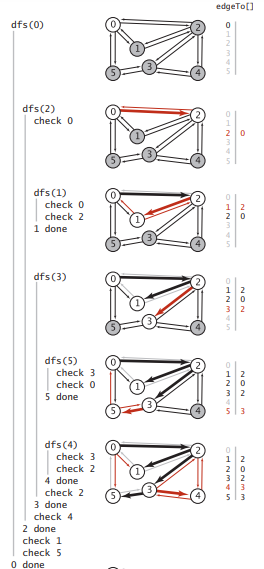
深度优先搜索可以遍历图中所有的顶点和边,利用DFS可以解决图中的一些问题:
- 连通性问题:给定的两个顶点是否相连
- 单点问题,路径问题:某一起点与任意联通顶点的路径
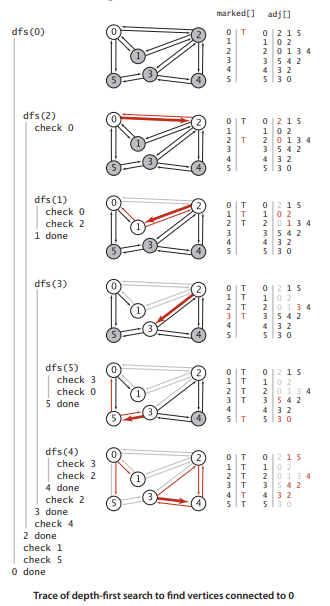
下面为利用DFS查找图中的路径的算法程序下图为DFS搜索路径的轨迹实例图1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
public class DepthFirstPaths {
private boolean[] marked;//用于标记顶点是否被访问过
private int[] edgeTo; //记录从起点到一个顶点的路径上的最后一个顶点
private int s;
public DepthFirstPaths(Graph G,int s){
this.s=s;
marked=new boolean[G.V()];
edgeTo=new int[G.V()];
dfs(G,s);
}
//深度优先算法DFS
private void dfs(Graph G,int v){
marked[v]=true;
for(int w:G.adj(v)){
if(!marked[w]){
edgeTo[w]=v;
dfs(G,w);
}
}
}
public boolean hasPathTo(int v){
return marked[v];
}
//返回起点到某个顶点的路径
public Iterable<Integer> pathTo(int v){
if(!hasPathTo(v)){
return null;
}
Stack<Integer> path=new Stack<Integer>();
for(int x=v;x!=s;x=edgeTo[x]){
path.push(x);
}
path.push(s);
return path;
}
}
广度优先搜索
我们常要解决的问题是图中两个点之间最短的路径问题,DFS可以找出两点间的联通路径,却没办法找到最短的路径,但广度优先搜索可以解决这个问题。
在广度优先搜索中我们是按照与起点的距离的顺序遍历所有结点,这里用到了队列(先进先出,就近遍历);
首先将起点标记并加入队列,重复以下步骤直到队列为空:
- 将队列中的下一个顶点v出队,并将其标记;
- 将与v相邻且未被标记的顶点按顺序依次入队;
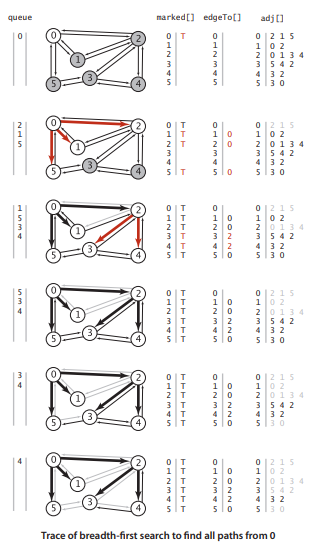
BFS搜索路径算法:下图为BFS实例中搜索轨迹图:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
public class BreadthFirstPaths {
private boolean[] marked;//用于标记顶点是否被访问过
private int[] edgeTo; //记录从起点到一个顶点的路径上的最后一个顶点
private int s;
public BreadthFirstPaths(Graph G,int s){
this.s=s;
marked=new boolean[G.V()];
edgeTo=new int[G.V()];
bfs(G,s);
}
//广度优先算法BFS
private void bfs(Graph G,int s){
Queue<Integer> queue=new Queue<Integer>();
marked[s]=true;
queue.enqueue(s);
while(!queue.isEmpty()){
int v=queue.dequeue();
for(int w:G.adj(v)){
if(!marked[w]){
edgeTo[w]=v;
marked[w]=true;
queue.enqueue(w);
}
}
}
}
public boolean hasPathTo(int v){
return marked[v];
}
//返回起点到某个顶点的路径
public Iterable<Integer> pathTo(int v){
if(!hasPathTo(v)){
return null;
}
Stack<Integer> path=new Stack<Integer>();
for(int x=v;x!=s;x=edgeTo[x]){
path.push(x);
}
path.push(s);
return path;
}
}
用BFS检测给定的图是无环的吗。
用BFS检测是否是二分图(即任意一条边的两个顶点都不属于同一连通集)
DFS和BFS具有不同的搜索路径:
深度优先搜索是不断深入图中,探索距离起点越来越远的顶点,只有碰到访问过的顶点或者死胡同时才返回到最近的顶点;
广度优先搜索像扇面一样前进,它只有访问了一个顶点附近相邻的所有顶点之后才继续向前探索;
DFS的路径通常长而曲折,而BFS路径短而整齐直接。
如下图所示两种搜索方式的路径对比:

连通分量
DFS解决连通性问题
用深度优先搜索来查找图中所有的连通分量的算法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36public class CC{
private boolean[] marked; //用来标记顶点是否被访问过
private int[] id; //用来标记所属的连通集
private int count; //表示连通集
public CC(Graph G){
marked=new boolean(G.V());
id=new int(G.V());
for(int s=0;s<G.V();s++){
if(!marked[s]){
dfs(G,s);
count++;
}
}
}
public dfs(Graph G,int v){
marked[v]=true;
id[v]=count;
for(int s:G.adj[v]){
if(!marked[s]){
dfs(G,s);
}
}
}
//判断两个顶点是否属于同一个连通分量
public boolean connect(int v,int w){
return id[v]==id[w];
}
//返回顶点所在的连通集
public int id(int v){
return id[v];
}
//返回有几个连通分量
public int count(){
return count;
}
}
下图为搜索图中所有连通分量的轨迹:
并查集解决连通性问题
Union_Find:并查集能解决动态连通性问题,union()会将两个分量合并到同一连通分量,fins()会返回给定点所在的连通分量的标识符,connect()会判断两个点是否在同一连通分量,count()会返回连通分量的数量。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//并查集抽象类,关键的是抽象的方法find和union
abstract class Union_Find {
protected int[] id;
protected int count;
public Union_Find(int N){
count=N;
id=new int[N];
for(int i=0;i<N;i++){
id[i]=i;
}
}
public int count(){
return count;
}
public boolean connected(int p,int q){
return find(p)==find(q);
}
public abstract int find(int p);
public abstract void union(int p,int q);
}
Quick Find
快速查找算法:id[]这个数组标记着结点所在的连通集,将在同一连通集的结点的id[]值设置为同一个值,当将两个连通集合并的时候,将一个连通集内的所有结点的id[]值改为另一个连通集的id[]值。
这种算法不适合处理大型问题,以为find速度很快,但是union速度非常慢,需要将其中一个连通分量中的所有节点 id 值都修改为另一个节点的 id 值
1 |
|
Quick Union
需要一种快速union的算法,只需要修改一下id[]数组的结构,每个点对应的id[]元素都是同一连通分量的其它点,这叫做链接。一个结点由链接找到指向它的另一个结点,这个节点再继续查找,以此类推知道找到这个连通集的根节点,类似以树结构。
union操作时只需将一个连通集的根节点指向另一个连通集的根节点
这种算法union操作很高效,find操作时间复杂度和树的高度成正比,最坏情况下树的高度为结点个数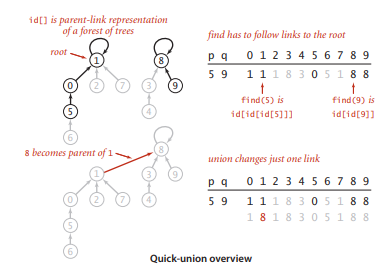
quick-union算法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21//快速合并算法
public class Quick_Union extends Union_Find {
public Quick_Union(int N) {
super(N);
}
public int find(int p){
while(p!=id[p]){
p=id[p];
}
return p;
}
public void union(int p,int q){
int pID=find(p);
int qID=find(q);
if(pID==qID){
return;
}
id[pID]=qID;
count--;
}
}
加权Quick Union
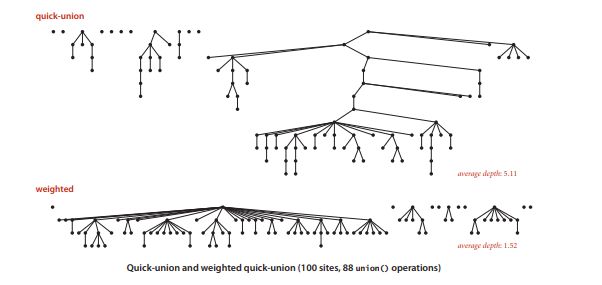
为了防止quick-union最坏情况的发生,改进quick-union为加权quick-union算法
做法是记录被一个连通集的大小,union时将小的连通集指向大的连通集,这样生成的连通集会很平衡
加权的quick-union算法能够实现lgN对数级别的性能
1 |
|
有向图
有向图:由一组顶点和一组有向的边组成的。
有向图也用邻接表表示,与无向图不同的是无向图制定了a通向b,即a->b,那么同时就有b->a;但有向图不一样,当指定了a->b没有b->a。
有向图的数据结构只有addEdg()方法不同,去掉注释的语句:1
2
3
4
5public void addEdg(int v,int w){
adj[v].add(w);
#adj[w].add(v);
E++;
}
有向图的可达性
单点可达性:一个图和一个起点s–>是否存在从s到v的有向路径
多点可达性: 一个图和一个顶点集合–>是否存在从集合任意顶点到达给定顶点的有向路径
1 |
|
图中的环和有向无环图
有些问题是不允许图中有有向环的
可以用DFS检测一个图是否是有向无环图
代码如下:
1 | public class DirectedCycle { |
拓扑排序
对于有向图深度优先搜索只会访问图中每个顶点一次
将DFS访问的顶点存储在一个数据结构,遍历这个数据结构就能按一定顺序得到图中所有的顶点
根据数据结构的不同和保存节点的时间不同分成三种顺序:
- 前序:队列->在递归调用前将点入队
- 后序:队列->在递归调用之后将顶点入队
- 逆后序:栈->在递归之后将顶点入栈
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
public class DepthFirstOrder {
private boolean[] marked;
private Queue<Integer> pre; //所有顶点的前序排列
private Queue<Integer> post; //所有顶点的后序排列
private Stack<Integer> reverpost; //所有顶点的逆后排序
public DepthFirstOrder(Digraph G){
pre=new Queue<Integer>();
post=new Queue<Integer>();
reverpost=new Stack<Integer>();
marked=new boolean[G.V()];
for(int v=0;v<G.V();v++){
if(!marked[v]){
dfs(G,v);
}
}
}
private void dfs(Digraph G,int v){
pre.enqueue(v); //递归之前入队
marked[v]=true;
for(int w:G.adj(v)){
if(!marked[w]){
dfs(G,w);
}
}
post.enqueue(v); //低估后入队
reverpost.push(v);
}
public Iterable<Integer> pre(){
return pre;
}
public Iterable<Integer> post(){
return post;
}
public Iterable<Integer> reverpost(){
return reverpost;
}
}
拓扑排序:是对有向无环图的排序,给定一幅图,将所有顶点排序,使所有的有向边从排在前面的元素指向排在后面的元素,如果有一条路径从v->w,那么排序后v就要在w的前面
拓扑排序主要用来对有依赖关系的事物排序
一个有向无环图的拓扑排序顺序即所有顶点逆后序排列
给定的一个图先判断是否无环,然后利用DepthFirstOrder返回逆后序顶点就是拓扑排序的结果1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class Topological {
private Iterable<Integer> order;
public Topological(Digraph G){
DirectedCycle dc=new DirectedCycle(G); //判断是否是有向无环图
if(!dc.hasCycle()){
DepthFirstOrder dfs=new DepthFirstOrder(G);
order=dfs.reverpost();
}
}
public Iterable<Integer> order(){
return order;
}
}
有向图的强连通性
强连通:有向图中如果两个顶点互相可达则这两个点是强连通的
强连通分量:有向图中的一个强连通分量是图中的一个最大的顶点集合C,对于C中的每一对顶点u和v,u和v是强连通的
识别计算有向图中的强连通分量:Kosaraju算法
- 对于一个有向图G,使用DepthFirstOrder来计算它的反向图GR的逆后序排序列
- 按照的到的GR的逆后序列的顺序在G中进行深度优先搜索
下列代码可以判断两个顶点是否强连通,查找并计算所有的强连通分量1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38public class KosarajuSCC {
private boolean[] marked; //用来标记顶点是否被访问过
private int[] id;//记录强连通分量的标识
private int count;//记录强连通分量的数量
public KosarajuSCC(Digraph G){
marked=new boolean[G.V()];
id=new int[G.V()];
DepthFirstOrder order=new DepthFirstOrder(G.reverse());//计算GR的逆后序列
for(int s:order.reverpost()){
if(!marked[s]){
dfs(G,s);
count++;
}
}
}
private void dfs(Digraph G, int v) {
marked[v]=true;
id[v]=count;
for(int w:G.adj(v)){
if(!marked[w]){
dfs(G,w);
}
}
}
//判断两顶点是否强连通
public boolean stronglyConnected(int v,int w){
return id[v]==id[w];
}
//返回顶点所在的强连通分量
public int id(int v){
return id[v];
}
//返回强连通分量的数量
public int count(){
return count;
}
}