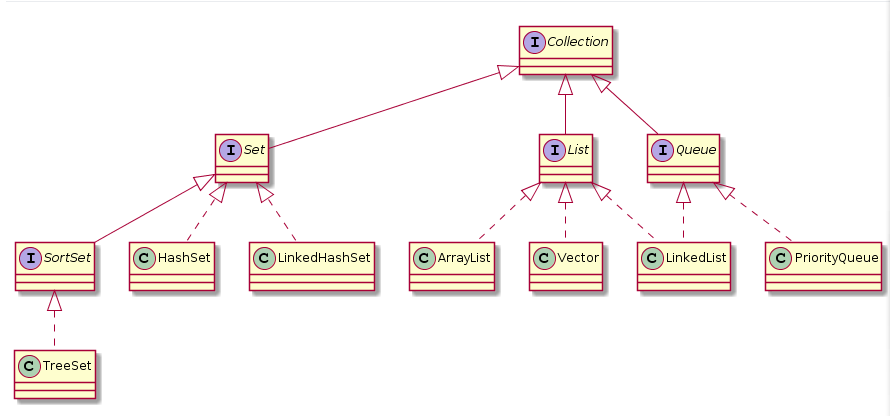
容器主要包括 Collection 和 Map 两种,Collection 存储着对象的集合,而 Map 存储着键值对(两个对象)的映射表。
- Collection接口的子接口包括:Set接口和List接口
- Set接口的实现类主要有:HashSet、TreeSet、LinkedHashSet等
- List接口的实现类主要有:ArrayList、LinkedList、Stack以及Vector等
- Map接口的实现类主要有:HashMap、TreeMap、Hashtable、ConcurrentHashMap以及Properties等
Collection
网上博客教程:
https://blog.csdn.net/feiyanaffection/article/details/81394745
public interface Collection<E> extends Iterable<E>
Collection接口的常用方法
添加功能
boolean add(E e) boolean addAll(Collection<? extends E> c) 添加一个集合的元素删除功能
void clear() 从此集合中删除所有元素 boolean remove(Object o) boolean removeAll(Collection<?> c) 删除指定集合中包含的所有此集合的元素判断功能
boolean contains(Object o) 如果此集合包含指定的元素,则返回true boolean containsAll(Collection<?> c) 如果此集合包含指定 集合中的所有元素,则返回true boolean isEmpty() 如果此集合不包含元素,则返回 true长度功能
int size() 返回此集合中的元素数
交集功能
boolean retainAll(Collection<?> c) 两个集合都有的元素 a.retainAll(b) a和b做交集,结果保存在a中,b不变,返回的boolean值表示a是否发生变化
一、List
public interface List<E>
extends Collection<E>
List-有序集合(存储和取出的元素一致)(也称为序列 ),可以精确控制列表中每个元素的插入位置,通过整数索引(列表中的位置)访问元素,并搜索列表中的元素,列表通常允许重复的元素
1. List的特有方法
void add(int index,E element) 将指定的元素插入此列表中的指定位置
E get(int index) 返回此列表中指定位置的元素
ListIterator<E> listIterator() 返回列表中的列表迭代器(按适当的顺序)
E remove(int index) 删除该列表中指定位置的元素
E set(int index, E element) 用指定的元素替换此列表中指定位置的元素
2. List的类型分类
各类型特点对比:
- ArrarList:底层数据结构是数组,支持随机访问,查询快,增删慢
- 线程不安全,效率高
- Vector: 底层数据结构是数组,查询快,增删慢
- 线程安全,效率低
- LinkedList:低层数据结构是双向链表,查询慢(只能顺序访问),但是可以快速地在链表中间插入和删除元素增删快。LinkedList还可以用作栈、队列、双向队列
- 线程不安全,效率高
3. LinkedList
LinkedList的基本方法:
public void addFirst(E e) 在列表的头部插入元素 public void addLast(E e) 在列表尾部插入元素 public E getFirst() 返回此列表中的第一个元素。 public E getLast() 返回此列表中的最后一个元素 public E removeFirst() 从此列表中删除并返回第一个元素 public E removeLast() 从此列表中删除并返回最后一个元素
4. ArrayList与LinkedList的区别和适用场景
Arraylist:
- 优点:ArrayList是实现了基于动态数组的数据结构,因为地址连续,一旦数据存储好了,查询操作效率会比较高(在内存里是连着放的)。
- 缺点:因为地址连续, ArrayList要移动数据,所以插入和删除操作效率比较低。
LinkedList:
- 优点:LinkedList基于链表的数据结构,地址是任意的,所以在开辟内存空间的时候不需要等一个连续的地址,对于新增和删除操作add和remove,LinedList比较占优势。LinkedList 适用于要头尾操作或插入指定位置的场景
- 缺点:因为LinkedList要移动指针,所以查询操作性能比较低。
适用场景分析:
- 当需要对数据进行对此访问的情况下选用ArrayList,
- 当需要对数据进行多次增加删除修改时采用LinkedList。
5. ArrayList与Vector的区别和适用场景
ArrayList有三个构造方法:
public ArrayList(int initialCapacity)//构造一个具有指定初始容量的空列表。 public ArrayList() //默认构造一个初始容量为10的空列表。 public ArrayList(Collection<? extends E> c)//构造一个包含指定 collection 的元素的列表Vector有四个构造方法:
public Vector()//使用指定的初始容量和等于0的容量增量构造一个空向量。 public Vector(int initialCapacity)//构造一个空向量,使其内部数据数组的大小,其标准容量增量为零。 public Vector(Collection<? extends E> c)//构造一个包含指定 collection 中的元素的向量 public Vector(int initialCapacity,int capacityIncrement)//使用指定的初始容量和容量增量构造一个空的向量
这两个类都实现了 List 接口(List 接口继承了 Collection 接口),他们都是有序集合,即存储在这两个集合中的元素位置都是有顺序的,相当于一种动态的数组,我们以后可以按位置索引来取出某个元素,并且其中的数据是允许重复的,这是与 HashSet 之类的集合的最大不同处,HashSet 之类的集合不可以按索引号去检索其中的元素,也不允许有重复的元素。
- ArrayList和Vector都是用数组实现的,主要有这么三个区别:
- 1).Vector是多线程安全的,线程安全就是说多线程访问同一代码,不会产生不确定的结果。而ArrayList不是,这个可以从源码中看出,Vector类中的方法很多有synchronized进行修饰,这样就导致了Vector在效率上无法与ArrayList相比;
- 2)两个都是采用的线性连续空间存储元素,但是当空间不足的时候,两个类的增加方式是不同。Vector 每次扩容请求其大小的 2 倍(也可以通过构造函数设置增长的容量),而 ArrayList 是 1.5 倍。
- 3)Vector可以设置增长因子,而ArrayList不可以。
- 4)Vector是一种老的动态数组,是线程同步的,效率很低,一般不赞成使用。
使用场景:
- Vector是线程同步的,所以它也是线程安全的,而ArrayList是线程异步的,是不安全的。如果不考虑到线程的安全因素,一般用ArrayList效率比较高。
- 如果集合中的元素的数目大于目前集合数组的长度时,在集合中使用数据量比较大的数据,用Vector有一定的优势。
二、迭代器
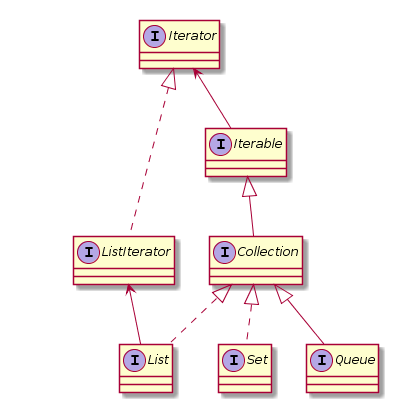
迭代器是一种对象,它的功能是遍历并选择序列中的对象。
Iterator迭代器
Collection 实现了 Iterable 接口,其中的 iterator() 方法能够产生一个 Iterator 对象,通过这个对象就可以迭代遍历 Collection 中的元素。
Collection获取迭代器的方法:
Iterator<E> iterator() 返回此集合中的元素的迭代器
Iterator接口的常用方法:
boolean hasNext() 判断集合里是否有元素
E next() 获取元素并移动到下一个元素
集合的使用步骤:
A:创建集合对象
Collection c = new ArrayList();
B:创建元素对象
Object obj=.....
C:元素添加到集合
c.add(obj)
D:遍历集合元素
a:用过集合获取迭代器对象
Iterator it = c.iterator()
b:通过迭代器对象的hasNext()方法判断是否有元素
boolean flag = it.hasNext()
c:通过迭代器next()方法获取元素
Object obje = it.next()
集合的遍历(以List类型为例,Set同理)
第一种:迭代器遍历
//部分伪代码,E代表某种类型
List<E> list=new List<E>();
list.add(E a);
list.add(E b);
//假设list里已经添加多个E类型的对象,可以遍历
Iterator it=list.iterator();
while(it.hasNext()){
E e=it.next();
print(e);
}
第二种:foreach方法(增强for循环)
List<E> list=new List<E>(); list.add(E a); list.add(E b); ....... for(E e:list){ print(e);
}
-------------------
List<String> list = new ArrayList<>();
list.add("a");
list.add("b");
for (String item : list) {
System.out.println(item);
}
ListIterator
ListIterator是Iterator的子类,只用于List类集合,Iterator只能单向移动,而ListIterator可以双向移动
主要方法:
继承了Iterator的功能(hasNext(),next())
boolean hasPrevious() 返回true如果遍历反向列表,列表迭代器有多个元素
E previous() 返回列表中的上一个元素,并向后移动光标位置
int nextIndex() 返回由后续调用返回的元素的索引next()
int previousIndex() 返回由后续调用previous()返回的元素的索引
三、Set
1. Set类型
与List集合不同的是,Set集合不保存重复的元素
TreeSet:基于红黑树实现,支持有序性操作,例如根据一个范围查找元素>的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)
HashSet:基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的
LinkedHashSet:具有 HashSet的查找效率,且内部使用双向链表维护元素的插入顺序
HashSet提供最快的查询速度,TreeSet保持元素处于排序状态,LinkedHashSet以插入顺序保存元素
1)HashSet
HashSet 是基于 HashMap 实现的,HashSet的值存放于HashMap的key上,HashMap的value统一为PRESENT,因此 HashSet 的实现比较简单,相关 HashSet 的操作,基本上都是直接调用底层 HashMap 的相关方法来完成,HashSet 不允许重复的值。
HashSet保证集合元素唯一性的原理:
HashSet线程不安全,效率高,可以存储null元素,元素的唯一性是靠所存储元素类型是否重写hashCode()和equals()方法来保证的,如果没有重写这两个方法,则无法保证元素的唯一性。
具体实现唯一性的比较过程:
存储元素首先会使用hash()算法函数生成一个int类型hashCode散列值,然后已经的所存储的元素的hashCode值比较:
- 如果hashCode不相等,则所存储的两个对象一定不相等,此时存储当前的新的hashCode值处的元素对象;
- 如果hashCode相等,存储元素的对象还是不一定相等,此时会调用equals()方法判断两个对象的内容是否相等,如果内容相等,那么就是同一个对象,无需存储;如果比较的内容不相等,那么就是不同的对象,就该存储了,此时就要采用哈希的解决地址冲突算法,在当前hashCode值处类似一个新的链表, 在同一个hashCode值的后面存储存储不同的对象,这样就保证了元素的唯一性。
Set的实现类的集合对象中不能够有重复元素,HashSet也一样他是使用了一种标识来确定元素的不重复,HashSet用一种算法来保证HashSet中的元素是不重复的, HashSet采用哈希算法,底层用数组存储数据。默认初始化容量16,加载因子0.75。
Object类中的hashCode()的方法是所有子类都会继承这个方法,这个方法会用Hash算法算出一个Hash(哈希)码值返回,HashSet会用Hash码值去和数组长度取模, 模(这个模就是对象要存放在数组中的位置)相同时才会判断数组中的元素和要加入的对象的内容是否相同,如果不同才会添加进去。
2)TreeSet
TreeSet底层数据结构采用二叉树来实现,元素唯一且已经排好序;唯一性同样需要重写hashCode和equals()方法,二叉树结构保证了元素的有序性。
根据构造方法不同,分为自然排序(无参构造)和比较器排序(有参构造):
- 自然排序要求元素必须实现Compareable接口,并重写里面的compareTo()方法,元素通过比较返回的int值来判断排序序列,返回0说明两个对象相同,不需要存储;
比较器排需要在TreeSet初始化是时候传入一个实现Comparator接口的比较器对象,或者采用匿名内部类的方式new一个Comparator对象,重写里面的compare()方法;
基于TreeMap实现,使用元素的自然顺序对元素进行排序,或者使用set提供的comparator方法排序,
具体使用时取决于使用的构造方法A:自然排序:真正依赖于compareTo()方法,
这个方法定义在Comparable中,所以想重写该方法,就要实现Comparable接口,这个接口表示自然排序 例如:定义学生类时实现Comparable接口 public class Student implements Comparable<T>{ @override public int compareTo(T t){ .......... 主要条件 次要条件 } }B:比较器排序:comparator方法,
TreeSet的add()方法,是基于TreeMap方法的put()方法 public TreeSet(Comparator<? super E> comparator ) 构造一个新的,空的树集,根据指定的比较器进行排序 TreeSet<Student> ts = new TreeSet<Student>(new Comparator<Student>(){ public int compare(Student s1,Student s2){ ........... } };)
2. 适用场景分析
- TreeSet 是二插树(红黑树的树据结构)实现的,Treeset中的数据是自动排好序的,不允许放入null值
- HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束
- HashSet要求放入的对象必须实现HashCode()方法,放入的对象,是以hashcode码作为标识的,而具有相同内容的String对象,hashcode是一样,所以放入的内容不能重复。但是同一个类的对象可以放入不同的实例
适用场景分析:
HashSet是基于Hash算法实现的,其性能通常都优于TreeSet。为快速查找而设计的Set,我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet。
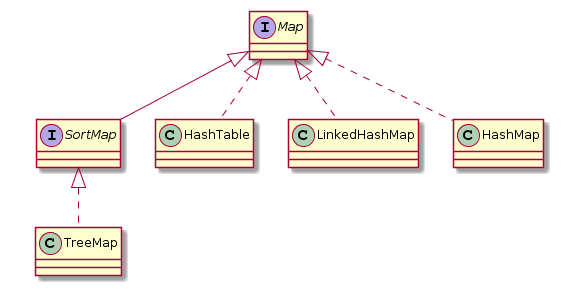
四、Map
public interface Map<K,V>
Map将键映射到值的对象。 地图不能包含重复的键; 每个键可以映射到最多一个值
1. Map的基本类型
- TreeMap:基于红黑树实现,保证唯一性和排序
- HashMap:基于哈希表实现
- HashTable:和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程可以同时写入 HashTable 并且不会导致数据不一致。它是遗留类,不应该去使用它。
- ConcurrentHashMap:现在可以使用 ConcurrentHashMap 来支持线程安全,并且 ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
- LinkedHashMap:使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序
- HashMap用来快速访问,TreeMap保持键排序,LinkedHashMap保持元素插入的顺序,也通过散列提供快速访问能力
2. Map基本方法功能
添加 V put(K key,V value) 将指定的值与该映射中的指定键相关联 如果键是第一次存储,直接存储元素,返回null; 如果不是第一次添加键值,就用新的值替换旧的值,并返回旧的值。 删除 void clear() 从该地图中删除所有的映射 V remove(Object key) 删除并返回 删除集合里存在的键,返回建的值,如果不存在返回null 判断 boolean containsKey(Object key) 如果此映射包含指定键的映射,则返回true boolean containsValue(Object value) 如果此映射将一个或多个键映射到指定的值,则返回true boolean isEmpty() 判断集合是否为空 获取 V get(Object key) 返回到指定键所映射的值 Set<Map.Entry<K,V>> entrySet() 返回此地图中包含的映射的Set视图 Set<K> keySet() 返回此地图中包含的键的Set视图 Collection<V> values() 返回此地图中包含的值的Collection视图 长度 int size() 返回此地图中键值映射的数量
Map集合的遍历
//创建集合 Map<String,String> map=new Map<String,String>(); //添加数据 map.put("德国","克罗斯"); map.put("法国","格列兹曼"); map.put("比利时","德布劳内");
方式一:
//获取键值集合
Set<String> set=map.keySet();
for(String s:set){
v=map.get(s);
System.out.println(s+"--->"+v);
}
方式二:
//获取映射Set集合
Set<Map.Entry<String,String> set=map.entrySet();
for(Map.Entry<String,String> m:set){
key=m.getKey();
value=m.getValue();
System.out.println(key+"--->"+value);
}
https://blog.csdn.net/ThinkWon/article/details/104588551/
HashMap 与 HashTable 有什么区别?
线程安全: HashMap 是非线程安全的,HashTable 是线程安全的;HashTable 内部的方法基本都经过 synchronized 修饰。(如果你要保证线程安全的话就使用 ConcurrentHashMap 吧!);
效率: 因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
对Null key 和Null value的支持: HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。但是在 HashTable 中 put 进的键值只要有一个 null,直接抛NullPointerException。
初始容量大小和每次扩充容量大小的不同: ①创建时如果不指定容量初始值,Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。②创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小。也就是说 HashMap 总是使用2的幂作为哈希表的大小,后面会介绍到为什么是2的幂次方。
底层数据结构: JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
推荐使用:在 Hashtable 的类注释可以看到,Hashtable 是保留类不建议使用,推荐在单线程环境下使用 HashMap 替代,如果需要多线程使用则用 ConcurrentHashMap 替代。
HashMap 和 ConcurrentHashMap 的区别
ConcurrentHashMap对整个桶数组进行了分割分段(Segment),然后在每一个分段上都用lock锁进行保护,相对于HashTable的synchronized锁的粒度更精细了一些,并发性能更好,而HashMap没有锁机制,不是线程安全的。(JDK1.8之后ConcurrentHashMap启用了一种全新的方式实现,利用CAS算法。)
HashMap的键值对允许有null,但是ConCurrentHashMap都不允许。
ConcurrentHashMap 和 Hashtable 的区别?
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
底层数据结构: JDK1.7的 ConcurrentHashMap 底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
实现线程安全的方式(重要): ① 在JDK1.7的时候,ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。(默认分配16个Segment,比Hashtable效率提高16倍。) 到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6以后 对 synchronized锁做了很多优化) 整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② Hashtable(同一把锁) :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。